Research Objective
A systematic deep-learning framework for automated binary PCOS detection from ovarian ultrasound images, benchmarking 18 modern vision architectures (CNNs + Vision Transformers + hybrids) under identical experimental conditions.
Model Training & Validation
A core part of my research involves training generative models to create synthetic medical images that closely resemble real scans. This expands the training data and makes the final detection models much more robust, especially when labelled data is scarce.

The synthetic generation process mimics complex features of medical imaging. Below are some of the samples my model generated during the initial training phase.

By using these techniques, I'm aiming to:
- Detect PCOS earlier: Reducing the number of cases that might otherwise be missed or delayed.
- Solve data shortages: Using AI to generate balanced datasets when real medical data is scarce.
- Build trust: Creating attention maps so clinical reviewers can see exactly what the AI is looking at.
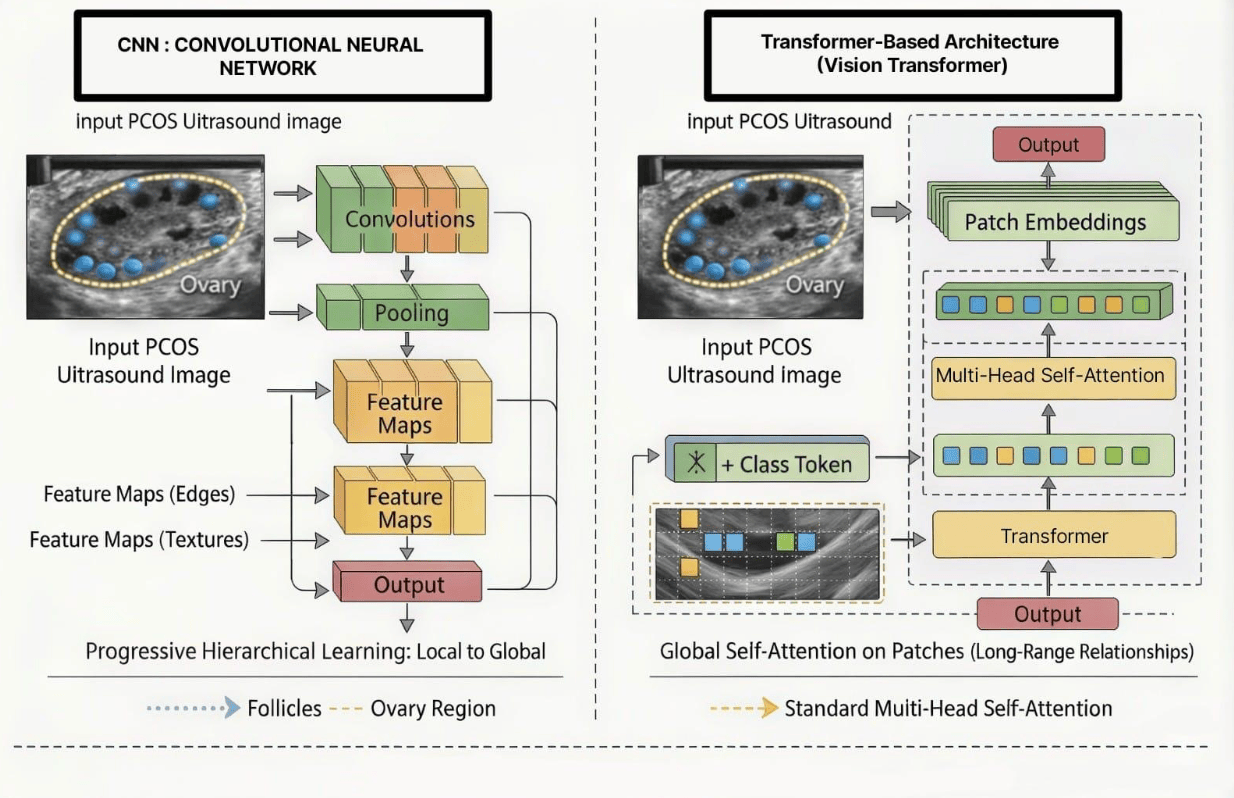
CNN vs Transformer - Architecture Comparison
For PCOS ultrasound classification I'm running a head-to-head between classical CNN stacks (progressive hierarchical features, local-to-global) and Vision Transformers (patch tokenisation + global self-attention). Both ingest the same ultrasound input, but they see the ovary very differently.
Three-stage deduplication pipeline
The public PCOS-XAI ultrasound dataset (11,784 images) had substantial duplicate and label-conflict noise. A novel three-stage pipeline cleaned it:
- MD5 cryptographic hashing - removes byte-identical duplicates.
- Perceptual hashing (pHash) + Hamming distance - removes near-duplicates (re-encoded / resized copies).
- Cross-class duplicate removal - drops images that appear in both PCOS and non-PCOS classes (label conflicts).
The pipeline removes 8,294 images (70.4%) and leaves a high-quality, unambiguously-labelled dataset of 3,490 images. Every architecture below was trained on the same deduplicated split, with ImageNet-pretrained transfer learning for 200 epochs.
Final test results - all 18 architectures after 200 epochs
All eighteen models (13 CNNs + 5 ViTs) were trained under standardised conditions for 200 epochs, with metrics logged at fixed intervals (50, 100, 150, 200). Reported below are the final test-set accuracy, F1-score, and AUC-ROC.
| Model | Loss | Accuracy | F1 | AUC-ROC |
|---|---|---|---|---|
| EfficientFormer-L1 | 0.0183 | 0.9981 | 0.9981 | 0.9999 |
| MobileViT-Small | 0.0021 | 0.9981 | 0.9981 | 1.0000 |
| ResNet34 | 0.0383 | 0.9962 | 0.9962 | 0.9998 |
| DenseNet169 | 0.0179 | 0.9962 | 0.9962 | 1.0000 |
| NextViT-Small | 0.0104 | 0.9962 | 0.9962 | 0.9999 |
| ResNet50 | 0.0318 | 0.9943 | 0.9943 | 1.0000 |
| DenseNet121 | 0.0467 | 0.9943 | 0.9943 | 0.9996 |
| EfficientNet-B0 | 0.1017 | 0.9943 | 0.9943 | 0.9975 |
| EfficientNet-B3 | 0.0655 | 0.9943 | 0.9943 | 0.9996 |
| ResNet18 | 0.0425 | 0.9924 | 0.9924 | 0.9995 |
| MobileNetV2 | 0.0640 | 0.9905 | 0.9905 | 0.9998 |
| MobileNetV3-Large | 0.0624 | 0.9905 | 0.9905 | 0.9997 |
| InceptionV3 | 0.0637 | 0.9905 | 0.9905 | 0.9991 |
| Xception | 0.0709 | 0.9905 | 0.9905 | 0.9996 |
| VGG19 | 0.0406 | 0.9866 | 0.9867 | 0.9986 |
| ViT-Base Patch16/224 | 0.3139 | 0.8263 | 0.8123 | 0.8993 |
| VGG16 | 0.5334 | 0.7748 | 0.6765 | 0.5000 |
| Swin Transformer Base | 0.5334 | 0.7748 | 0.6765 | 0.5248 |
Convergence trajectory (ResNet34, the top CNN)
To illustrate how the best pure-CNN converges across the 200-epoch schedule, ResNet34's training and validation metrics are shown at each checkpoint:
| Epoch | Train Loss | Train Ac | Val Loss | Val Ac |
|---|---|---|---|---|
| 50 | 0.0046 | 0.9984 | 0.0289 | 0.9943 |
| 100 | 0.0066 | 0.9975 | 0.0222 | 0.9962 |
| 150 | 0.0016 | 0.9992 | 0.0303 | 0.9962 |
| 200 | 0.0002 | 1.0000 | 0.0310 | 0.9962 |
| Final test | 0.0383 | Ac 0.9962 · F1 0.9962 · AUC 0.9998 | ||
Five principal findings
1. Data quality (novel deduplication pipeline)
The three-stage MD5 + pHash + cross-class pipeline cleaned the largest public PCOS-XAI ultrasound dataset, revealing and removing 70.4% (8,294 images) of corrupt data, including exact duplicates, near-duplicates, and label conflicts. This re-frames previously reported high-accuracy results and establishes a rigorously cleaned 3,490-image dataset as the new reliable baseline.
2. Superiority of efficient hybrid Transformer models
EfficientFormer-L1 and MobileViT-Small both hit 99.81% test accuracy (AUC up to 1.0000), surpassing every one of the 13 CNN architectures evaluated. Hybrid designs that combine CNN local feature extraction with Transformer global context modelling are clearly best-suited for moderate-size medical imaging datasets.
3. Failure of standard Transformer architectures
Pure attention models ViT-Base (82.63%) and Swin Transformer Base (77.48%) exhibited convergence failure on this dataset size, performing near chance for the minority class. This confirms that pure attention-based models are unsuitable for smaller real-world medical datasets without massive pre-training.
4. Benchmarking 18 architectures
The first large-scale, systematic comparison of 18 architectures (13 CNNs + 5 ViTs) for PCOS detection, all trained and evaluated under rigorously standardised conditions. The result is a fair, reproducible cross-architecture baseline that had previously been absent due to inconsistent protocols in earlier studies.
5. Evidence-based deployment guidance
Concrete recommendations:
- Maximum accuracy + interpretability: efficient hybrid ViTs (EfficientFormer-L1) - attention maps offer inherent visualisation for clinical validation.
- Resource-constrained edge / mobile: MobileNetV2 (3.5 M params, 99.05%) and EfficientNet-B0 (5 M params, 99.43%) - the best accuracy / efficiency trade-offs for real-time, on-device deployment.