CausalGrok: can grokking help a model learn from very little image data?
An ongoing investigation. Independent research.
The goal of this work is better generalisation when a dataset has very few images, the low-sample-size case. Picture a hospital with only a few hundred labelled images from a new scanner, and a model that still has to work on images from a different hospital it never trained on.
There are several ways to go after this. Grokking is the first one I am trying. Grokking is an effect where a small network first memorises its training data and then, if you keep training, later starts to generalise. The thing that drives that switch is a steady pressure toward the simplest answer that still fits the data. In this problem there are two answers a model could settle on: an easy shortcut (read the staining colour, guess the hospital) and the real one (read the tissue). The real answer is the simpler, more transferable one, so the first question I am chasing is whether grokking-style training can push a model onto it from only a few hundred images.
What this page is
Before running the full, properly-configured experiments, I wanted to see how a model behaves when the conditions and hyperparameters grokking needs are not set up: a quick check of the default and off-recipe settings to understand the landscape first. This page reports that check. It is one early step in the direction above.
The setup
I used Camelyon17 (via WILDS), a public dataset of small stained tissue images labelled tumour or normal, collected from five different hospitals. The hospitals stain and scan a little differently, so a "new domain" here simply means a hospital the model never trained on. I trained an ordinary image network (ResNet-18) from scratch on three hospitals, tuned on a fourth, and tested on a fifth, held-out hospital, using only 300 to 1000 training images.
I compared two training recipes that are identical except for three settings. The grokking recipe is the one I am pursuing; the plain recipe is the standard baseline I compare it against.
| Setting | Plain recipe (baseline) | Grokking recipe (the one I follow) |
|---|---|---|
| Pressure toward the simplest answer (weight decay) | low, 1e-4 | high, 5e-3 (50× more) |
| Starting weight size (init scale) | normal, 1× | large, 4× |
| Grokking speed-up (Grokfast) | off | on |
| Optimiser, learning rate, batch, length | same for both: AdamW, 1e-3, batch 32, 3000 passes | |
What I saw: ungrokking
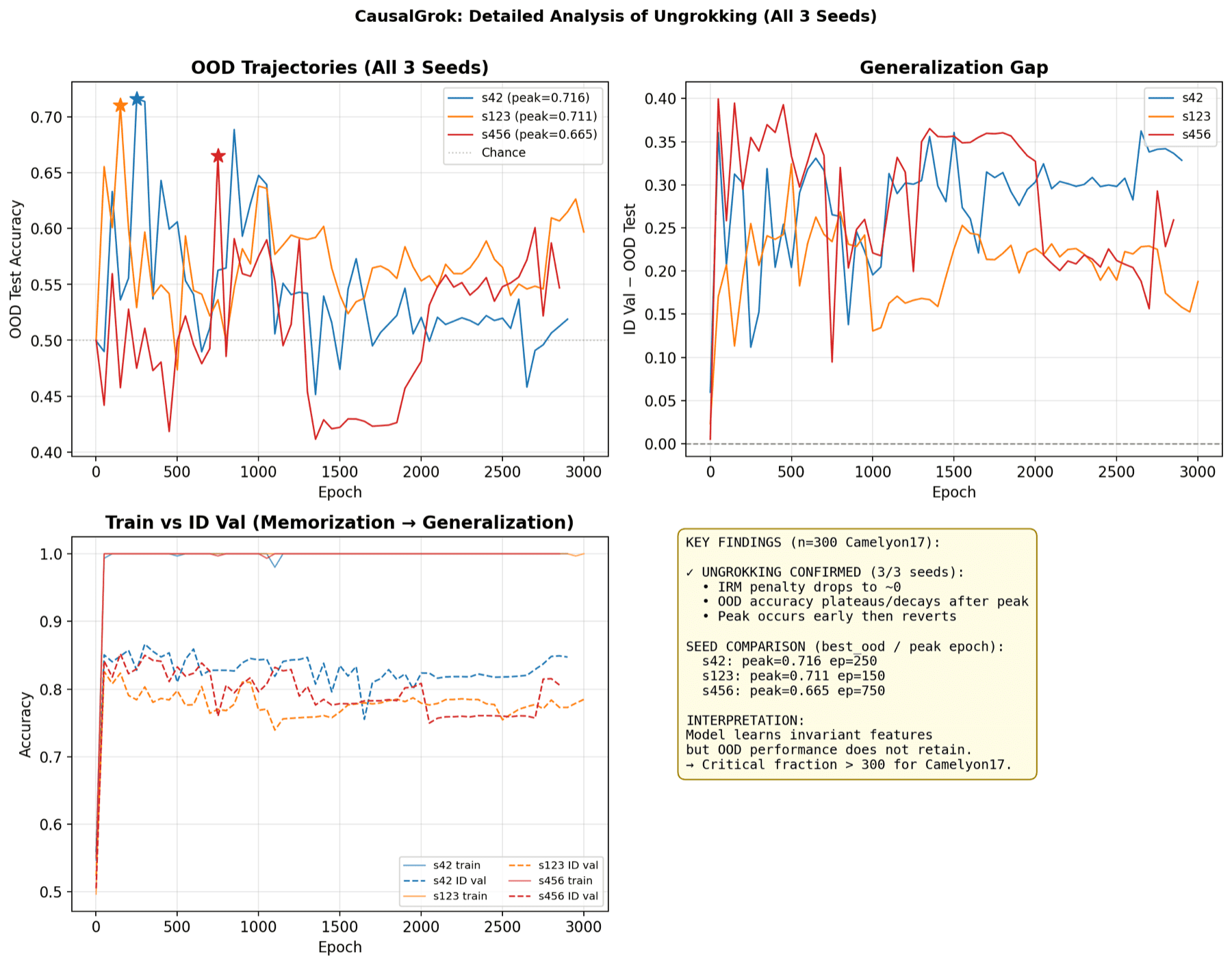
Across several dataset sizes and seeds, accuracy on the unseen hospital rose to an early peak and then slowly fell for the rest of training, in every run, even though the model stayed perfect on its own training images. That is the opposite of a grokking curve, which stays flat and then jumps up late; the grokking recipe scored no better than plain training (0.71 versus 0.75 at 1000 images).
This points to a wider takeaway worth stating plainly: generalising later is not the same as generalising better. Across these runs the grokking recipe never beat plain training at any dataset size. A model that only starts to generalise late carries no built-in edge over one that generalises on time; the late jump moves the timing, not the ceiling. The useful question is when and why a model starts to generalise, not whether training it for longer makes it generalise any better.
I call this peak-then-decline shape ungrokking. The training code measures it directly, the drop from each run's best score to its final score, and flags it in every grokking run.
This is what the setup would produce: memorisation finishes in about 50 passes, and there is almost no training left after it.
What the check tells me
This run was a check of the default and off-recipe settings, and it points straight at the conditions grokking needs. Compared with the setups where grokking is known to show up, this run was missing three of them:
- A low starting point. Grokking starts from a model stuck near a coin-flip. Here the model already scored well above a coin-flip on the unseen hospital from the very first step, so there was no stuck phase for a late jump to rise out of.
- A much longer training run. Grokking only shows up after the model keeps training for hundreds of thousands of steps past the point where it has memorised. This run memorised within about 50 passes and never trained for anywhere near that long.
- Many balanced classes. Grokking is studied on tasks with many equally likely answers and no easy shortcut. This task had just two answers (tumour or normal), where even random features score above a coin-flip, so the model never had to drop the shortcut.
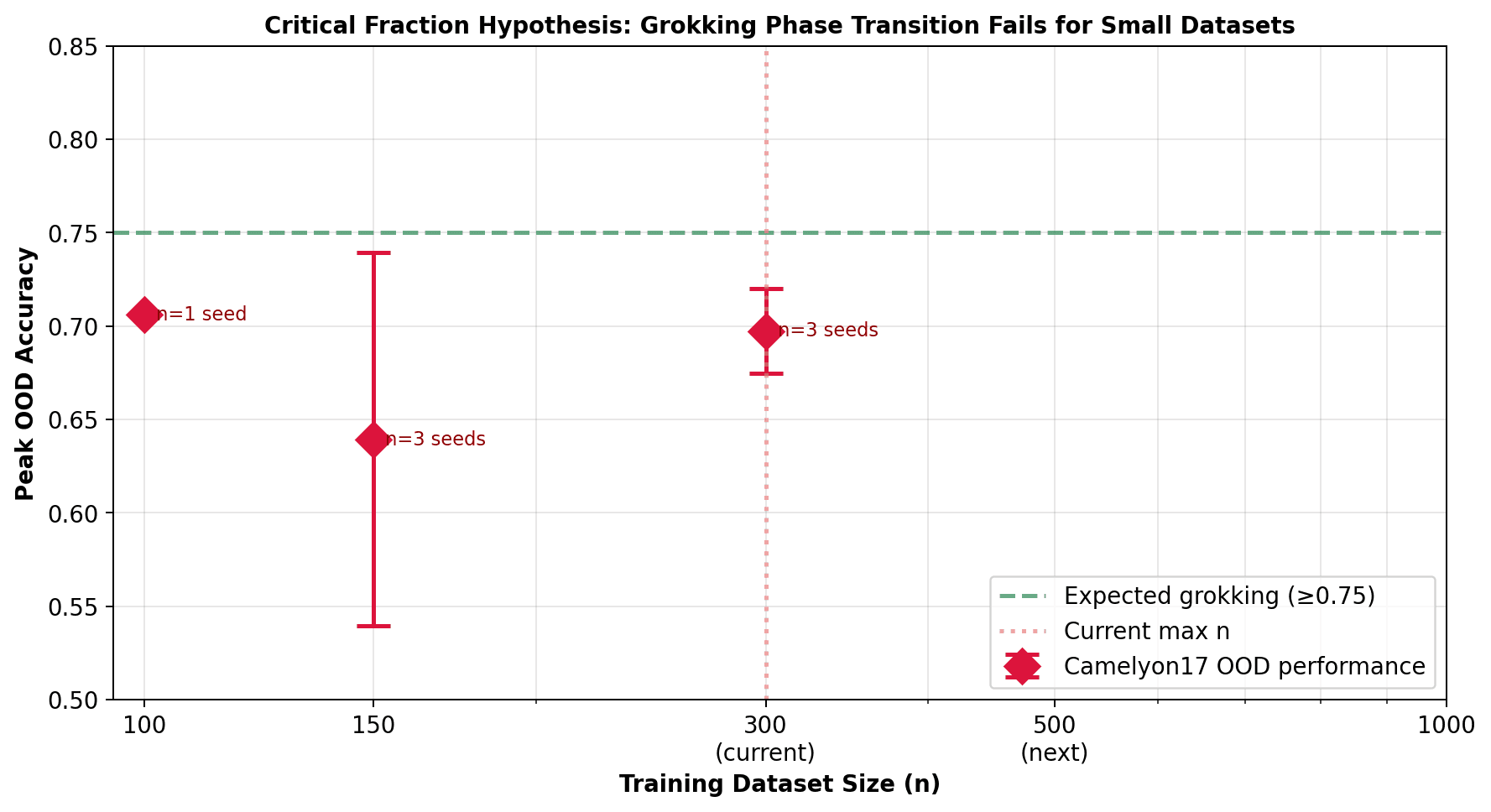
More data on its own does not change this. Across training-set sizes from 100 to 1000 images, the best unseen-hospital score stays flat and tracks plain training; it does not climb into a late jump.
A look inside the model
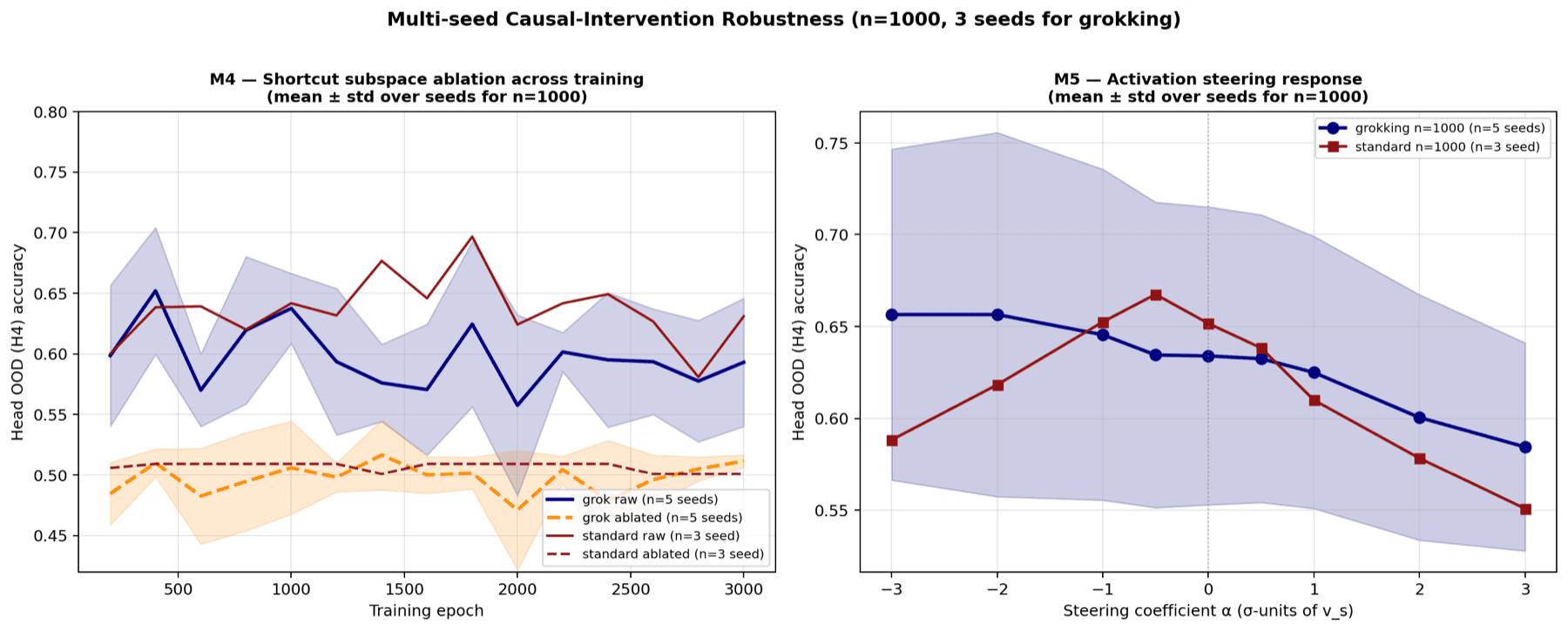
Even with no accuracy change, I ran four checks on the model's features to see whether the two recipes store the staining shortcut differently. The clearest one: when I push the features away from the shortcut, the grokking model tends to improve while plain training does not. The effect runs in the predicted direction and currently sits near 0.07, the kind of early signal the larger, properly-configured run is built to settle.
What I am running next
- What an image task has to look like to grok, the image criteria that put the three conditions in place.
- What dataset size is needed, and where the critical dataset size sits at which the behaviour changes.
- The three settings one at a time (weight decay, init scale, Grokfast), and in pairs, so any effect can be pinned on a single named setting.
- A task built to meet the three conditions, run for far longer, and compared against plain training at the same compute, with at least 10 seeds per recipe and standard significance tests reported either way.
Why it matters
Small, shifting datasets are everywhere: a new hospital scanner, a new satellite, a new factory camera, often with only 50 to 500 labelled images. Today's models lean on shortcuts and break on the next site. A training recipe that quietly pushes a model onto the real signal, without needing extra labels, would be useful straight away. That is what this direction is aimed at.